
Dog Pace¶
Action Space |
|
Observation Space |
|
import |
|
Description¶
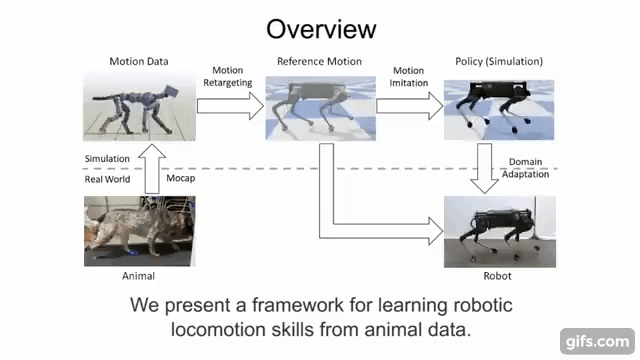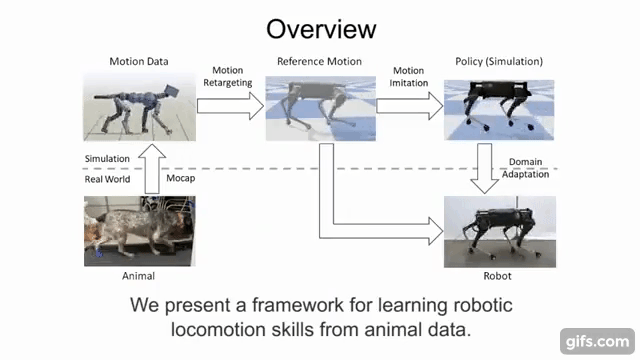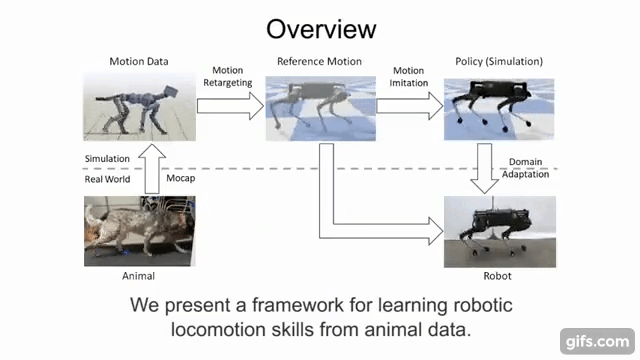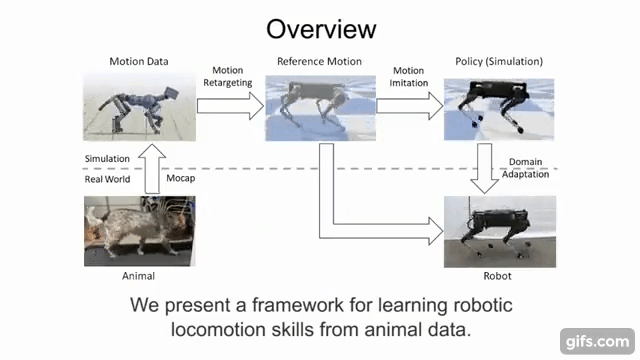
This quadruped locomotion environment was proposed by . They showed that by imitating skills of real-world reference motion data, a diverse repertoire of behaviors can be learned using a single learning-based approach. The quadruped is a legged robot which has 18 degrees of freedom (DoF), 3 actuated DoF per leg and 6 under-actuated DoF for the torso. The objective is to learn from imitating real animals. The observation is a reference motion of a desired skill, captured with
motion capture. The policy enables a quadruped to reproduce the skill in the real world, using the 12 actuated degrees of freedom of the legs. The controller runs at a control frequency of 30Hz.
Action Space¶
The actions specify target rotations for PD controllers at each joint. There are 12 controllable DoFs, three for each leg. The each action therefore corresponds to a target rotation for a single DoF. The action space is a Box(-2 \(\pi\),2 \(\pi\), (12,), float32).
For smooth motions, the PD targets are passed through a low-pass filter before being applied to the robot.
Observation Space¶
The observation space of this environment consists of the reference motion of the skills that need to be learned.
Rewards¶
The reward function is designed to encourage the policy to track a sequence of poses from the reference motion. Using reference motions, we avoid the need of designing skill-specific reward functions, enabling a common framework to learn a diverse array of behaviors. The reward at each step is:
Where the pose reward \(r^p_t\) reflects the difference between the reference joint rotations, \(\hat q^j_t\), and the robot joint rotations, \(q^j_t\):
The velocity reward \(r^v_t\) reflects the difference between the reference joint velocities, \(\hat{ \dot{q}}^j_t\), and the robot joint velocities, \(\dot{q}^j_t\):
The end-effector reward \(r^e_t\) encourages the robot to track the end-effector positions. \(x^e_t\) is the relative 3D position of the end-effector e with respect to the root:
Finally, the root pose reward \(r^{rp}_t\), and the root velocity reward \(r^{rv}_t\) encourage the robot to track the reference root motion. \(x^{root}_t\) is the root’s global position and \(\dot x^{root}_t\) is the root’s linear velocity, \(q^{root}_t\) is the root’s global porotationsition and \(\dot q^{root}_t\) is the root’s angular velocity :
Starting State¶
When resetting the environment, the robot’s position in the world is reset. The initial condition of the reference motion varies for very reset, to encourage a robust policy. The starting state therefore varies for every episode.
Episode End¶
The episode ends under two conditions. Either the task is completed, or the robot is in an unsafe condition.
Arguments¶
When creating the quadruped locomotion environment, we can pass several kwargs such as enable_rendering, mode, num_parallel_envs etc.
import gymnasium as gym
import rl_perf.domains.quadruped_locomotion
env = gym.make('QuadrupedLocomotion-v0', enable_rendering=False, ...)
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
bool |
|
If |
|
str |
|
Can be either |
|
int |
|
Number of parallel |
|
bool |
|
If |
|
Class |
|
Provide a |
|
|
A trajectory_generator that can potentially
modify the action and observation. Expected
to have |
Next, the reset method allows several options.
env.reset(seed, options)
Where the options should be passes as a Dict. The possible options are:
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
list |
|
A list of Floats. The desired joint angles after reset. If None, the robot will use its built-in value. |
|
Float |
|
The time (in seconds) needed to rotate all motors to the desired initial values. |
|
bool |
|
Whether to reset debug visualization camera on reset. |
Version History¶
v0: Initial versions release